创建
简单创建一个节点
1 | create( |
注意:create也可以和return搭配,直接返回结果。
当然,create也可以同时创建多个关系:
1 | create (m),(s) |
简单的创建一个关系线
比如已经有了两个节点,我们想关联上关系:
1 | match( |
如果我们想给这个线设置一些属性,也没什么问题:
1 | match( |
这样查出来的结果是:
可以看到,我们成功的设置了r.name.
当然,刚才我们是假设节点已经存在的情况,当然也可以假设不存在节点,直接创建节点+关系了。
1 | create p=(reba:Person{name: 'reba'})-[:WORK_AT]->(nazha:Person{name:'nazha'})<-[:WORK_AT]-(jt:Person{name: 'jt'}) |
成功图如下: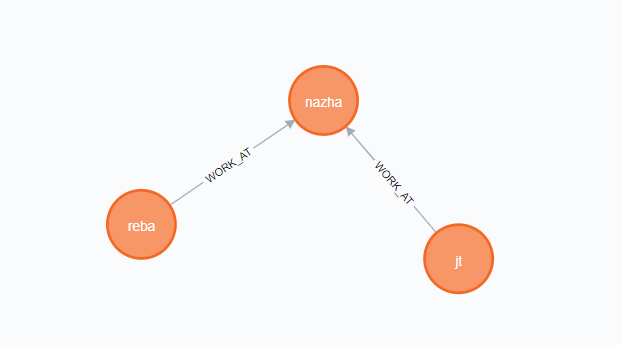
删除
清空数据库(慎用)
对于节点比较少的可以使用:
1 | match (n) detach delete n |
对于节点比较多的:
1、停掉服务;
2、删除 graph.db 目录;
3、重启服务。
delete 删除节点和关系
首先不删除干净连接的节点和关系是不能删除一个节点的。
比如首先有这个图: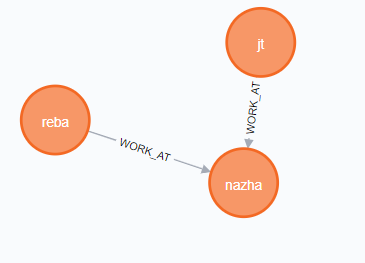
可见它是没有清除干净关系的,现在我们想删除它:
1 | match(p:Person{name:'jt'}) delete p |
执行的时候发现报Neo.ClientError.Schema.ConstraintValidationFailed的错。
我们找一个没有任何连接关系的进行删除,就没毛病了:
1 | match(p:Person{id:124}) delete p |
还有一种方式,就是删除一个节点,连带着它的关系全部删除,刚刚上面这种执行错误的,加一个detach关键字即可解决。
1 | match(p:Person{ |
还有一种情况,我们只想删除关系,该怎么办?当然也是能够解决的:
我们现在有这样一个关系图: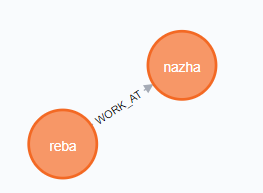
想把他们之间的关系删除掉,该怎么办?
1 | match(p:Person{name: "reba"})-[r:WORK_AT]->() delete r |
这样就能够把两者之间的关系给删除掉了!
remove 删除节点和关系中的属性字段
首先我们有这样一个节点: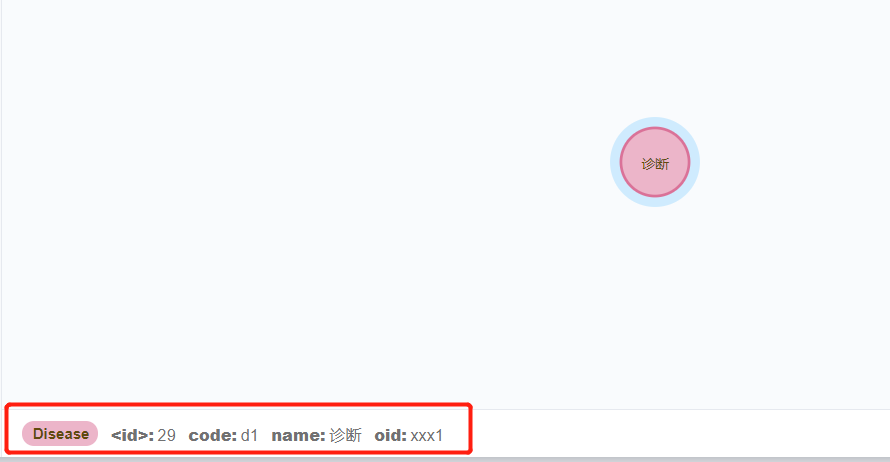
属性为:
1 | { |
用下面这段代码直接进行删除属性:1
2
3match(d:Disease{name:"诊断"})
remove d.code
return d.name, d.oid, d.code
结果变成: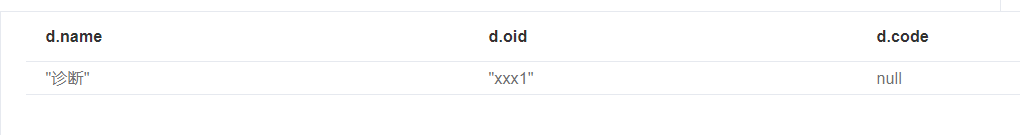
除了删除属性,我们还能删除label,什么是label呢?其实就是类名,比如用下面这段话,把刚刚诊断的类删掉:
1 | match(d:Disease{name:"诊断"}) |
改(SET)
修改/添加属性
最简单的进行修改一个属性:
1 | match(n {name: 'Andy'}) |
这里有一点需要注意的是,如果本身没有surname 这个属性,会自动增加属性。
还有一个高级写法,用到了case when:
1 | match(n{name: 'Andy'}) |
这里 如果不满足age=36 便不会执行下面的语句,这样的话,返回的就是一个null,比如:
一次修改/添加多个属性
1 | match(n{name: 'Peter'}) |
删除一个属性
将这个属性置为null,就是删除一个属性,如下:1
2MATCH (n { name: 'Andy' })
SET n.name = NULL RETURN n.name, n.age
删除所有的属性使用一个空的map和等号
这样即可删除节点所有的属性了。
1 | MATCH (p { name: 'Peter' }) |
完全copy一个节点或者关系
SET可用于将所有属性从一个节点或关系复制到另一个节点。这将删除复制到的节点或关系上的所有其他属性。
1 | MATCH (at { name: 'Andy' }),(pn { name: 'Peter' }) |
结果是: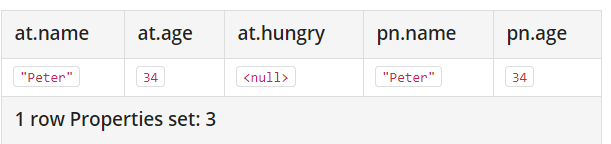
注意看两个参数!
设置一个节点属性所有从map中
1 | MATCH (p { name: 'Peter' }) |
请注意,这个操作会删除原来所有的节点!那有没有不删除所有的做法呢?当然有:
设置一个节点所有属性,但是不覆盖原来的属性
其实和上面几乎一样,就是把=变成+=
1 | match (p{name: 'Peter'}) |
修改类(label)
修改一个:1
2
3MATCH (n { name: 'Stefan' })
SET n:German
RETURN n.name, labels(n) AS labels
修改多个:
1 | match(n{name: 'Peter'}) |
查询
简单的查询一个节点
1 | match( |
简单进行条件类型的查询
1 | match( |
Return
return 的作用是在match匹配上了以后,选择哪些返回,如果能确定返回的属性,尽量不要全部返回!
- Return的语法很简单,需要什么就返回什么,*表示返回所有的。
比如:
1 | MATCH p =(a { name: 'A' })-[r]->(b) |
返回的结果就是所有的可能性:
- 在
return中,还可以像传统sql那样,通过as来改名:
1 | MATCH (a { name: 'A' }) |
- 对于没有属性的会返回一个
null,比如:1
2MATCH (n)
RETURN n.age
如果返回的两个结果,一个由age这个属性,一个没有,那么有的正常返回,没有的返回null。
- 还可以像Java一样返回一个布尔运算,并且返回的是多个元素也支持:
1
2MATCH (a { name: 'A' })
RETURN a.age > 30, "I'm a literal",(a)-->()
返回的是:
- 当然你也可以和
DISTINCT连着用1
2MATCH (a { name: 'A' })-->(b)
RETURN DISTINCT b
OPTIONAL MATCH
这个和match差不多,区别在于当没有查到东西的时候,会返回一个null
比如下面这句话:1
2
3
4
5match(p:Person{
name: 'reba'
})
optional match (p) -->(x)
return x
结果是:
可见是有值的,但是如果我们把指向方向换一下,变成:
1 | match(p:Person{ |
结果是: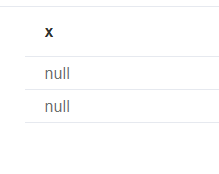
同样的,如果我们把optional去掉,结果是: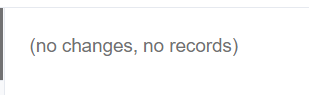
MERGE关键字
这个关键字基本上是把create和match合并到一起,先看一个最简单的用法:
1 | merge (robert:Critic{name: '111'}) |
本身是不存在这个节点的,所以会直接创建,那么把这句话再执行一遍,发现此时的作用只是相当于match了。
当然也可以从已经存在的节点中获取值,比如:
1 | MATCH (person:Person) |
从已经存在的节点中,获取一些属性值,然后进行复制。当然,这个操作可以是批量的!
比如此处的结果是: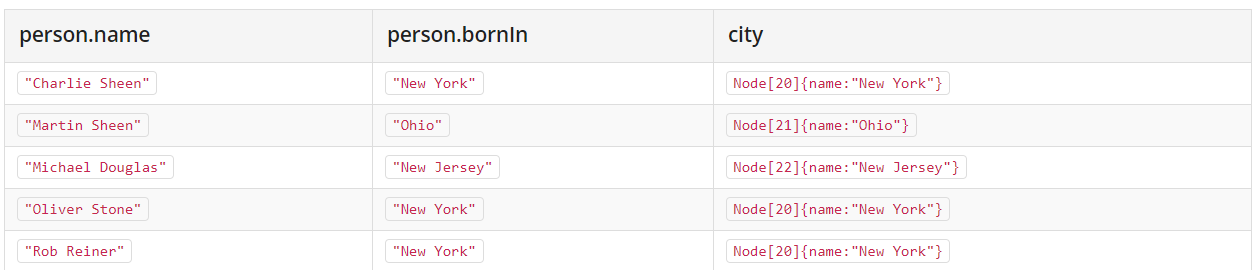
on create
这个实际上是一个限定条件,表达的是当创建的时候,才执行,不创建就不执行,比如:
1 | merge (c:Critic{name:'1112'}) |
这个语句中,如果数据库中已经存在了一个1112那么就不会set值,同样,如果不存在,那么就会执行set后面的部分。
on match
这个命令和上述表达差不多,不同的是它是匹配上了就进行set
1 | MERGE (person:Person) |
当然也可以同时设置多个属性值:
1 | MERGE (person:Person) |
on create 和on match 合并
1 | MERGE (keanu:Person { name: 'Keanu Reeves' }) |
现在数据库中是没有这个节点的,也就是说会进行创建,那么我们看看最后的结果:
很明显MATCH后面的没有执行!
Merge relationships
MERGE 同样也能被用来match或者create关系。
比如已经存在两个节点,想给他们MERGE一下关系:
1 | MATCH (charlie:Person { name: 'Charlie Sheen' }),(wallStreet:Movie { title: 'Wall Street' }) |
结果是: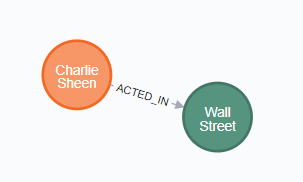
当然,我们也能够一下子处理多个关系,比如:
1 | MATCH (oliver:Person { name: 'Oliver Stone' }),(reiner:Person { name: 'Rob Reiner' }) |
最后结果是: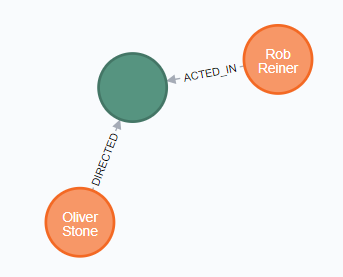
还可以创建一个无向的连接:
1 | MATCH (charlie:Person { name: 'Charlie Sheen' }),(oliver:Person { name: 'Oliver Stone' }) |
批量操作
有一些批量操作的写法,能够帮助我们快速创建大量节点和关系,比如:
1 | MATCH (person:Person) |
将所有Person中出生地和实际的城市直接挂钩!
最后结果是: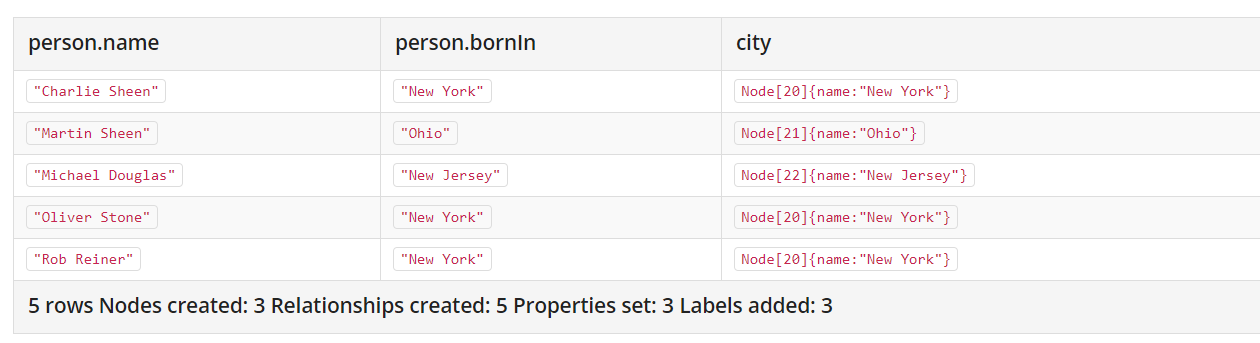
上面这句话,我们还可以改写下:
1 | MATCH (person:Person) |
限定条件WHERE
首先我们有这样一张图:
对于where,没什么好讲的,和传统的sql中差不多:
比如下面这句话:1
2
3MATCH (n)
WHERE n.name = 'Peter' XOR (n.age < 30 AND n.name = 'Timothy') OR NOT (n.name = 'Timothy' OR n.name = 'Peter')
RETURN n.name, n.age
对label进行过滤
下面这句话可以直接对label进行过滤:1
2
3MATCH (n)
WHERE n:Swedish
RETURN n.name, n.age
不固定属性的过滤
1 | with 'AGE' as propname |
结果是:
属性存在性校验
1 | MATCH (n) |

以xx字符串开头的写法
1 | MATCH (n) |
结果是:
以xx字符串结尾
1 | MATCH (n) |
字符串包含
1 | MATCH (n) |

NOT 的使用
1 | MATCH (n) |
正则表达式的使用
1 | MATCH (n) |
还有一种不区分大小写的写法:
1 | MATCH (n) |
结果是:
根据null过滤
1 | MATCH (person) |
结果是:

ORDER BY
首先记住,不能根据关系或者节点进行排序,只能根据属性!
然后看一个简单的写法:
1 | MATCH (n) |
一般order by都是放在return后面
SKIP
从头开始跳过几个数据,一般在Order by 的后面,如果没有order by 就放在return后面:
来看一个稍微高级点的写法:1
2
3
4MATCH (n)
RETURN n.name
ORDER BY n.name
SKIP toInteger(3*rand())+ 1
LIMIT
limit 一般是在最后了,控制展示的个数:
1 | MATCH (n) |
WITH
假设现在有这样一张图: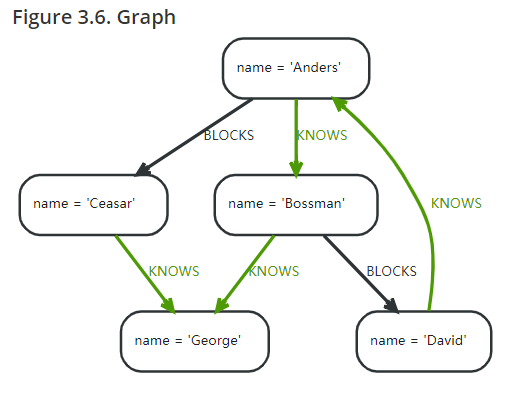
对聚合函数结果进行筛选
我们用这样一段话,来查询
1 | match(David{name: 'David'}) --(otherPerson)-->() |
结果是: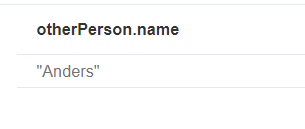
这句话表达的是David连接过去的节点,它向外连接关系大于1的那个节点。
所以很明显,就是Anders。
同理,
1 | match(Anders{name: 'Anders'}) --(otherPerson)-->() |
这个结果很明显就是Bossman了。
在使用collect之前对结果进行排序
1 | match(n) |
结果是: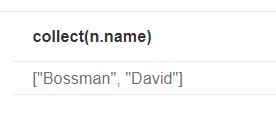
限制搜索路径分支
1 | MATCH (n { name: 'Anders' })--(m) |
最后结果是:
总结一下,With关键字是连接多个查询的结果,即将上一个查询的结果用作下一个查询的开始。
unwind
unwinding a list
我们先看这样一句话,初步了解下unwind 的用法:
1 | unwind [1, 2, 3, NULL] as x |
结果是: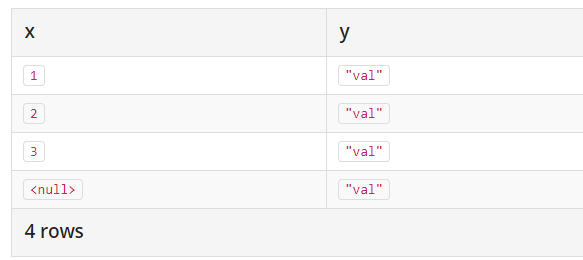
creating a distinct list
1 | with [1, 1, 2, 2] as coll |
结果是: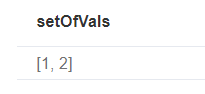
Using UNWIND with any expression returning a list
其实是在合并列表1
2
3with [1, 2] as a, [3, 4] as b
unwind (a + b) as x
return x
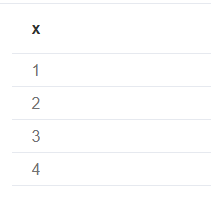
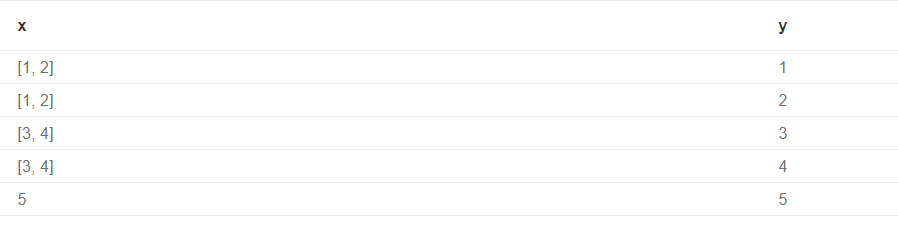
Using UNWIND with a list of lists
1 | with [[1, 2], [3, 4], 5] as nested |
Using UNWIND with an empty list
这是一个用法,只要unwind的是一个[],那么不管一起返回的是什么,都会返回一个0rows。
1 | unwind [] as empty |

Using UNWIND with an expression that is not a list
unwind可以被用来检测是不是一个list
1 | unwind null as x |
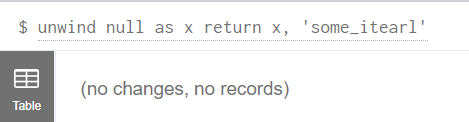
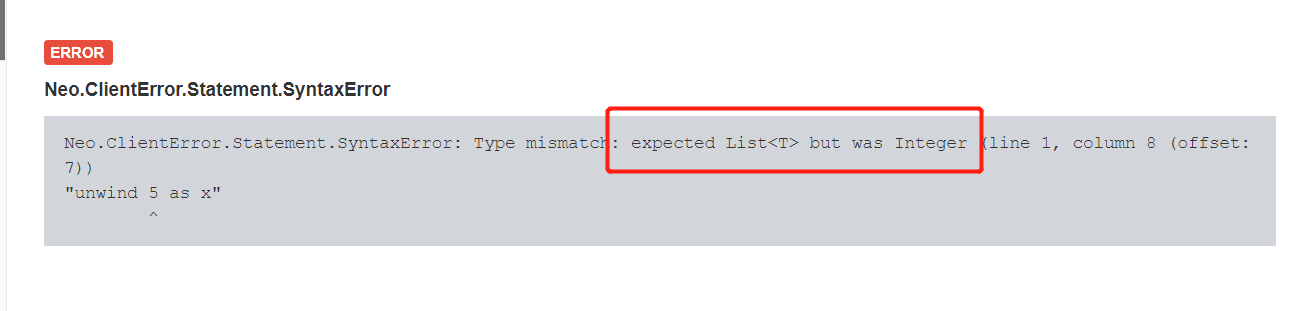
如果我们直接unwind一个数字,会报错:
1 | unwind 5 as x |
FOREACH
对于这样关系的一张图: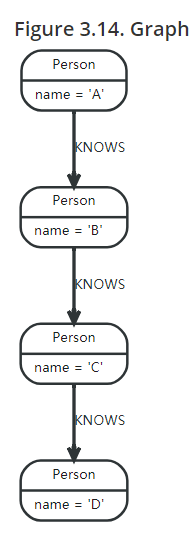
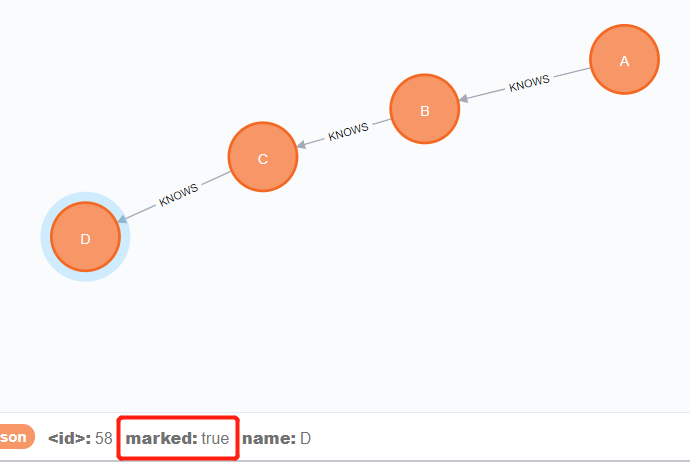
下面这句话,可以批量的进行修改属性1
2
3match p=(begin)-[*]->(END)
where begin.name = 'A' And END.name = 'D'
foreach(n in nodes(p)| set n.marked = TRUE)
结果是:
CALL
使用CALL可以调用一些函数,比如来个最简单的调用一个库函数:
1 | CALL `db`.`labels` |
这样子可以把我们的所有类名全部列出来:
但这一部分一般用到的应当不多,不作详细介绍。
UNION
union 就是把两个结果合并起来。
比如:1
2
3
4MATCH (n:Actor)
RETURN n.name AS name
UNION ALL MATCH (n:Movie)
RETURN n.title AS name
这样子查出来的结果是: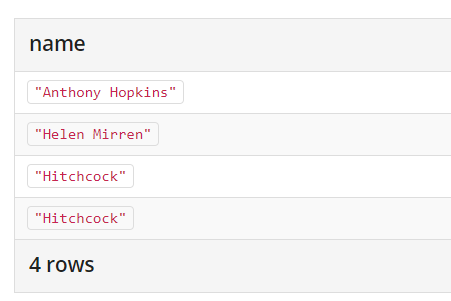
如果不用union all改直接用union呢?
1 | MATCH (n:Actor) |
结果是:
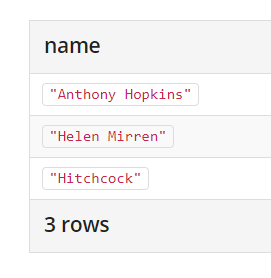
相当于取了个重