Attention机制首次在NLP领域被提出来是为了解决seq2seq模型的瓶颈问题,朴素encoder-decoder的问题是,只能用固定维度的最后一刻的encoder隐藏层来表示源语言Y,必须将此状态一直传递下去,这是个很麻烦的事情。事实上,早期的NMT在稍长一点的句子上效果就骤降。
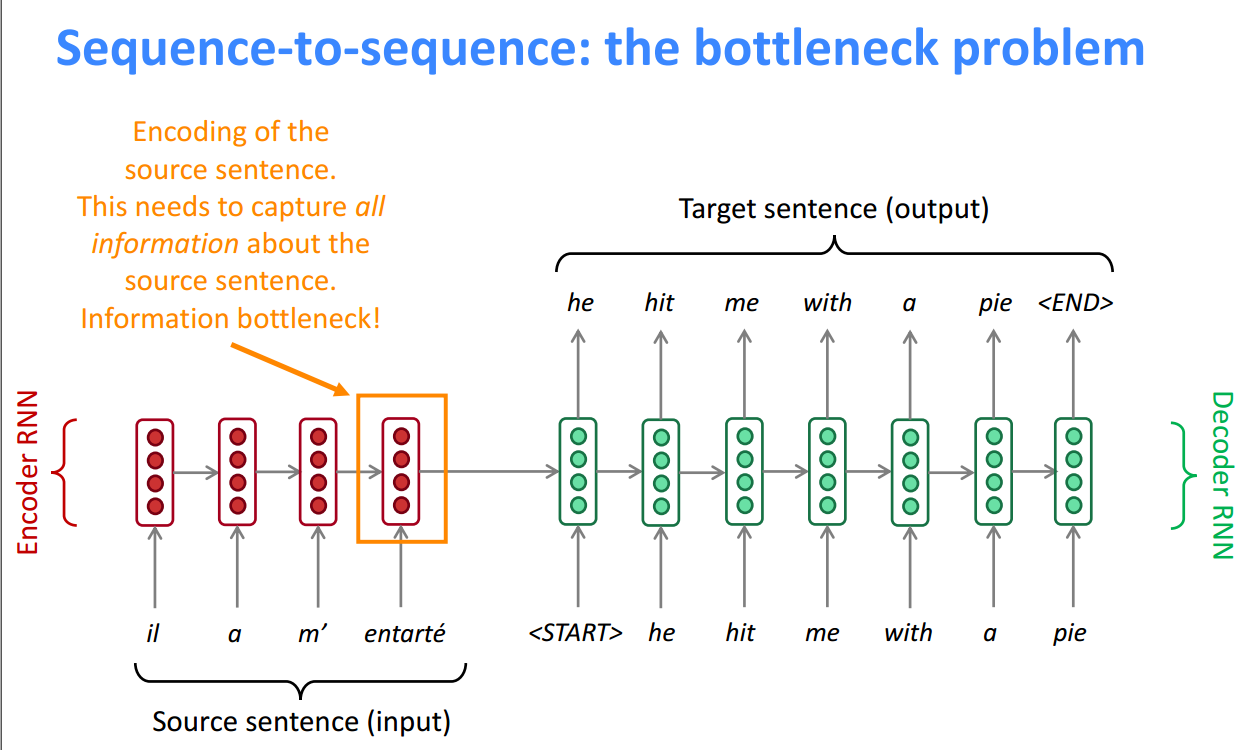
为了解决这个问题,Attention机制在Decoder的每一步都与Encoder直接相连接,集中注意力在原序列的某个部分。
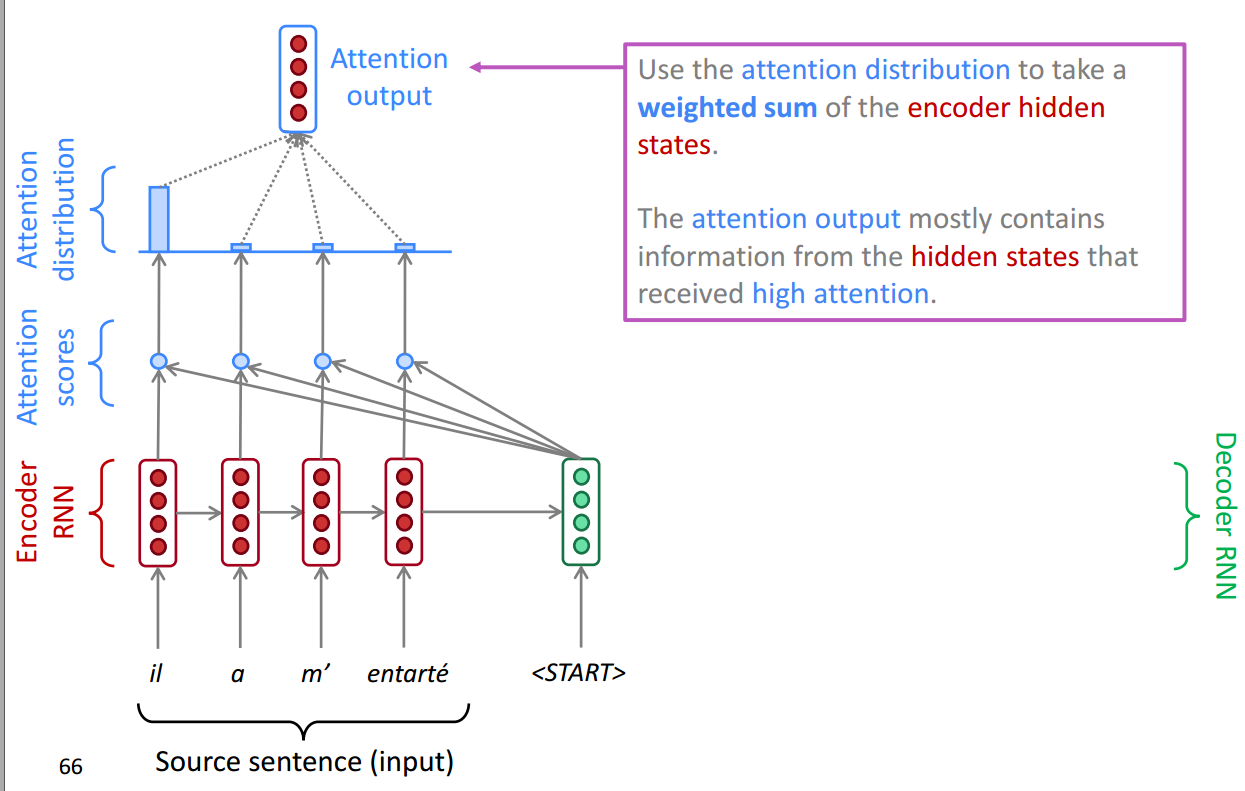
图解Attention步骤
首先针对一个翻译的任务,在Encoder部分,将每一步的输出存储下来。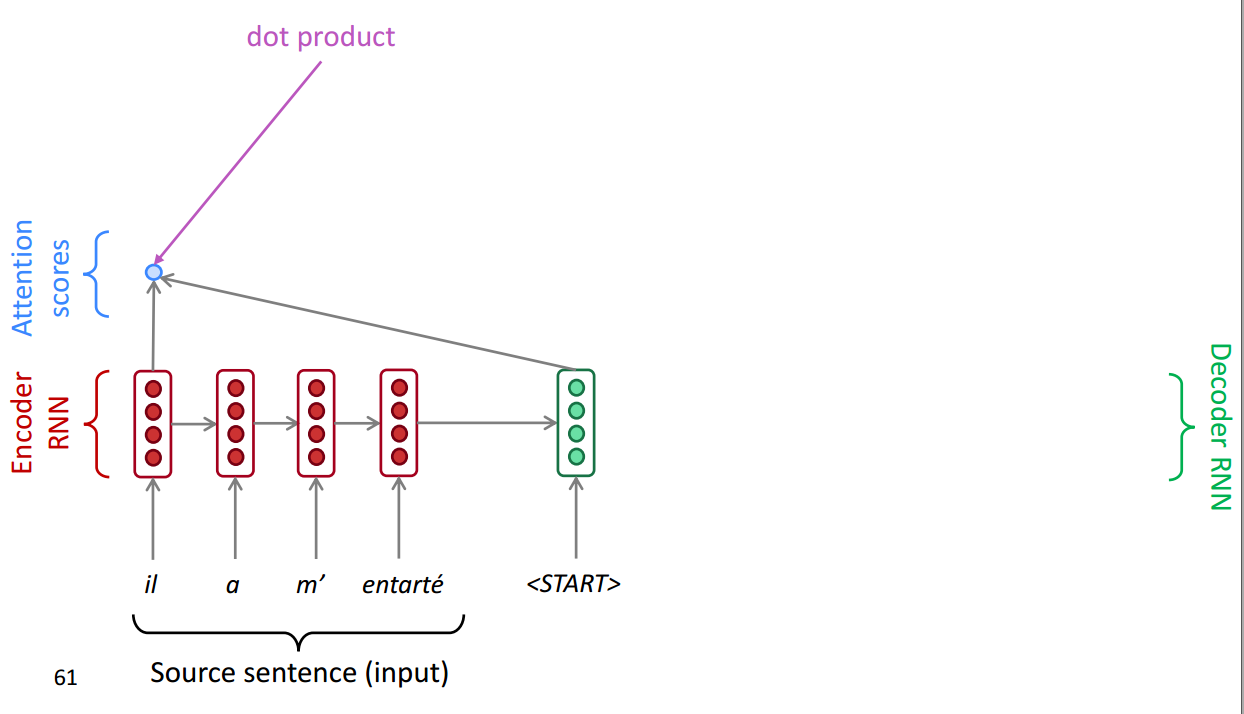
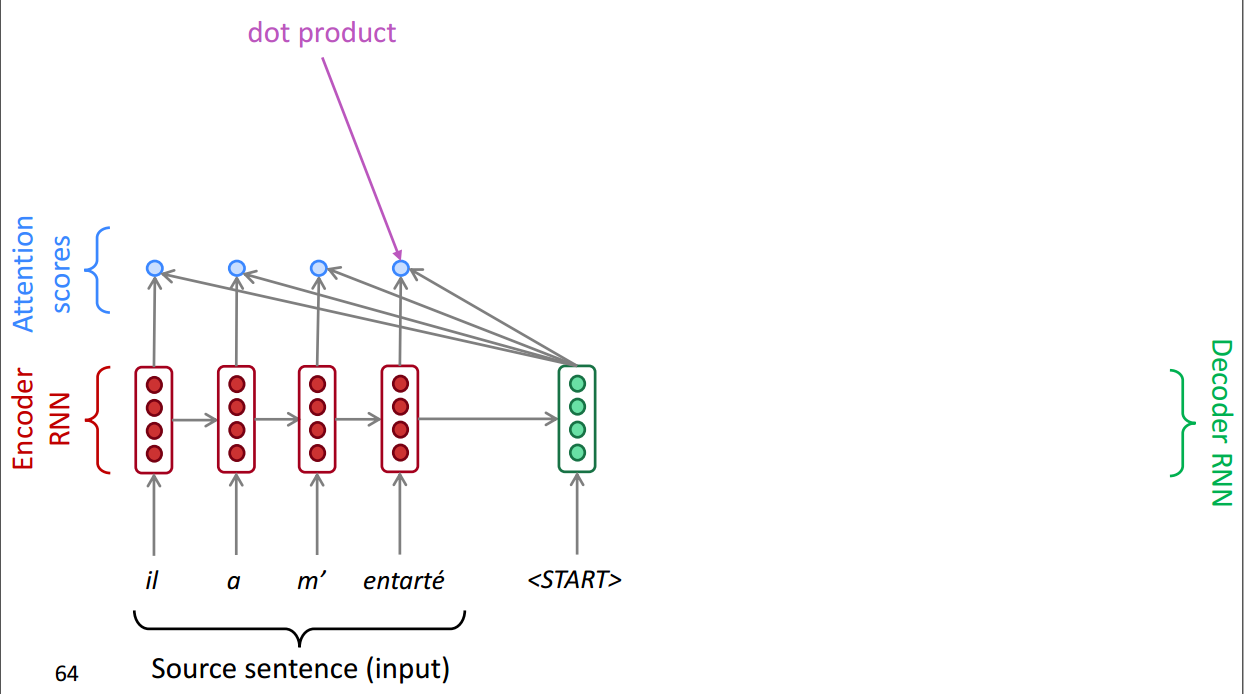
然后针对当前Decoder层的输入,我们加一层softmax层找到最应当集中注意力的。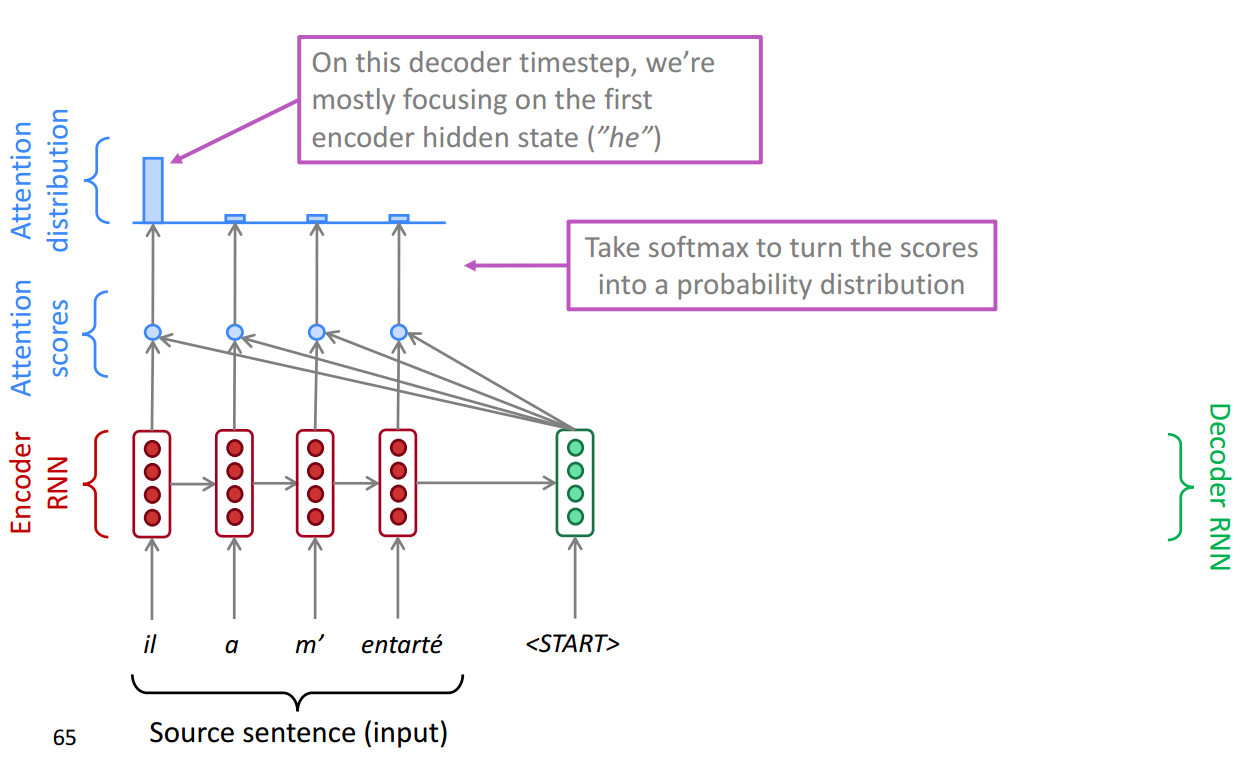
然后再将Attention Distribution 统一进行相加构成一层输出,也就是Attention output,这一层是经过当前Decoder层的某一步,集中注意力的结果了。
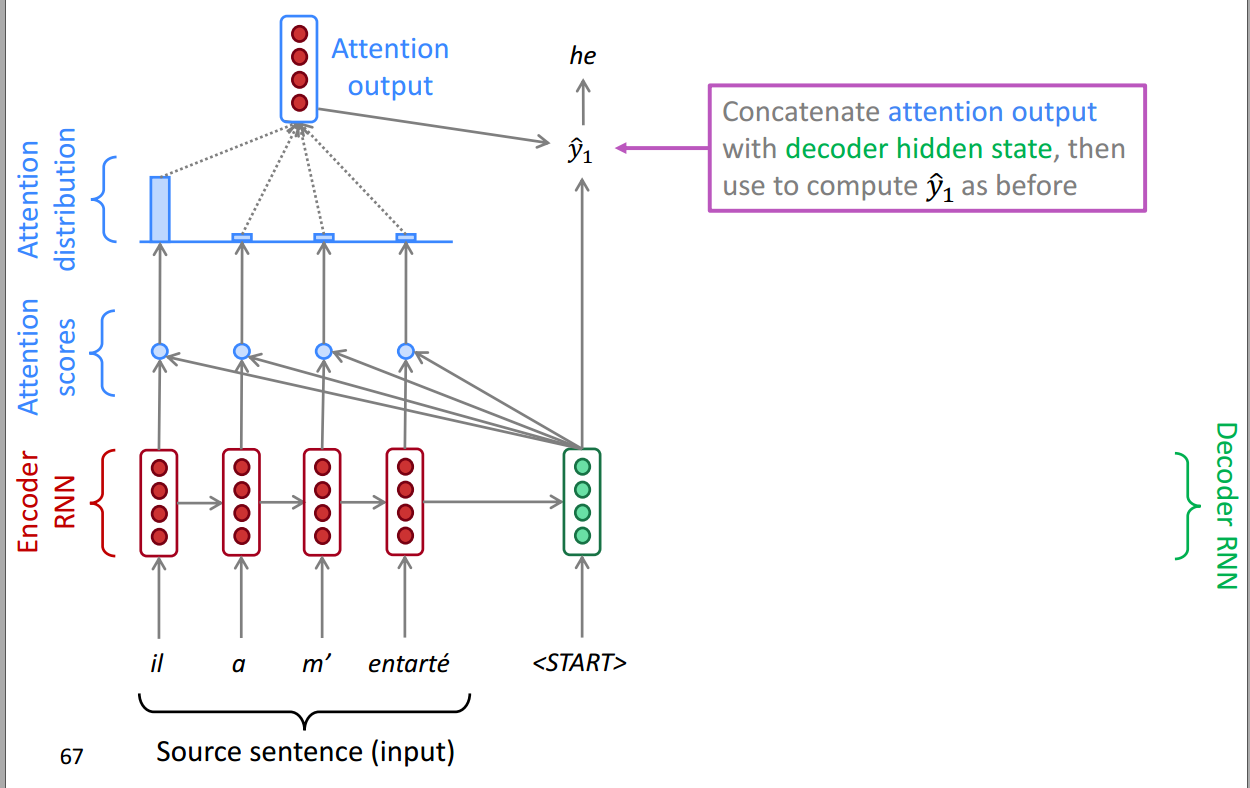
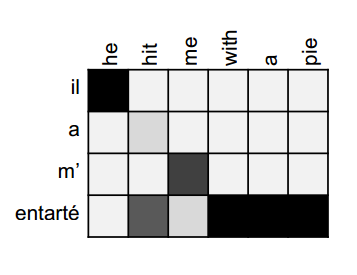
然后将注意力的输出和Decoder层当前的Hiddern state共同作为输入,得到一个输出,可以看到图中成功的预测出了单词he
同样的步骤在Decoder层的第二步: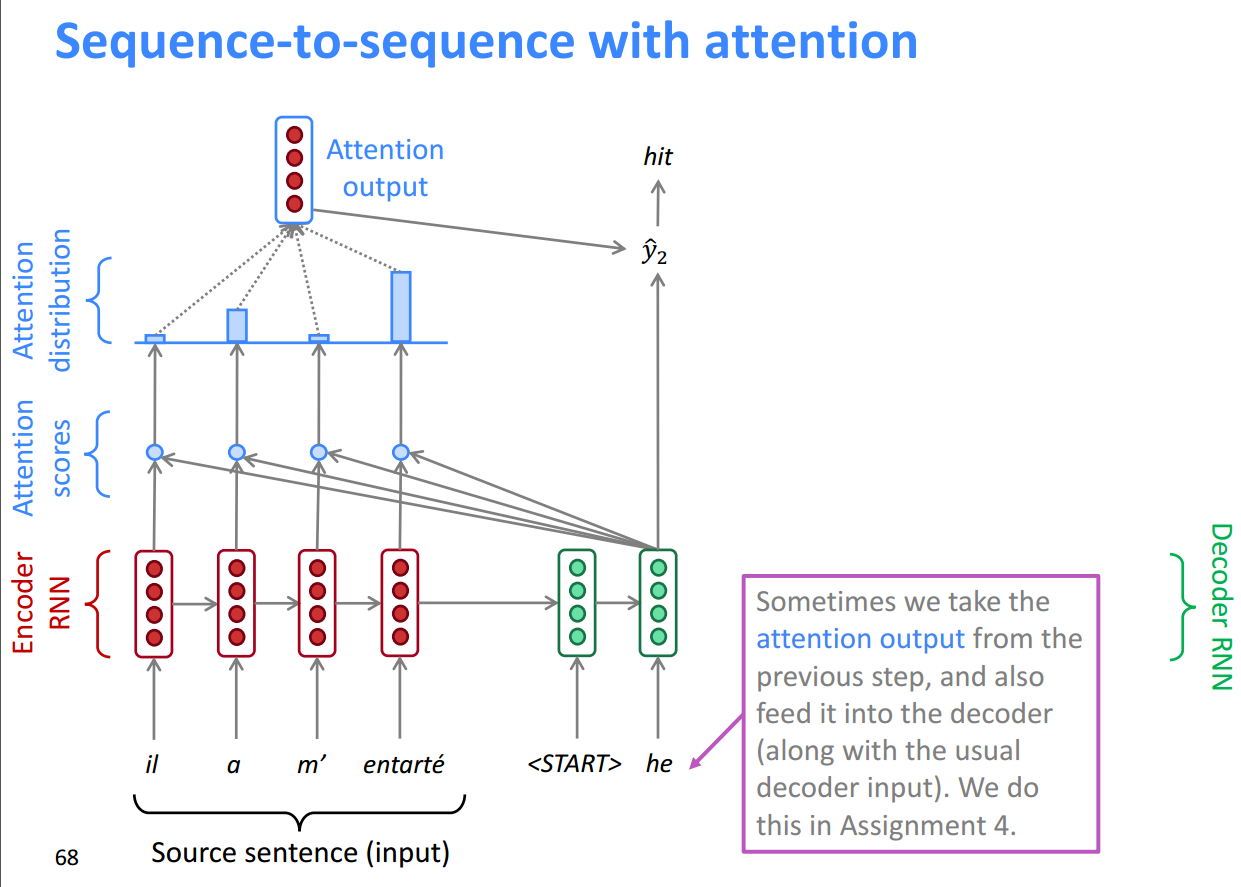
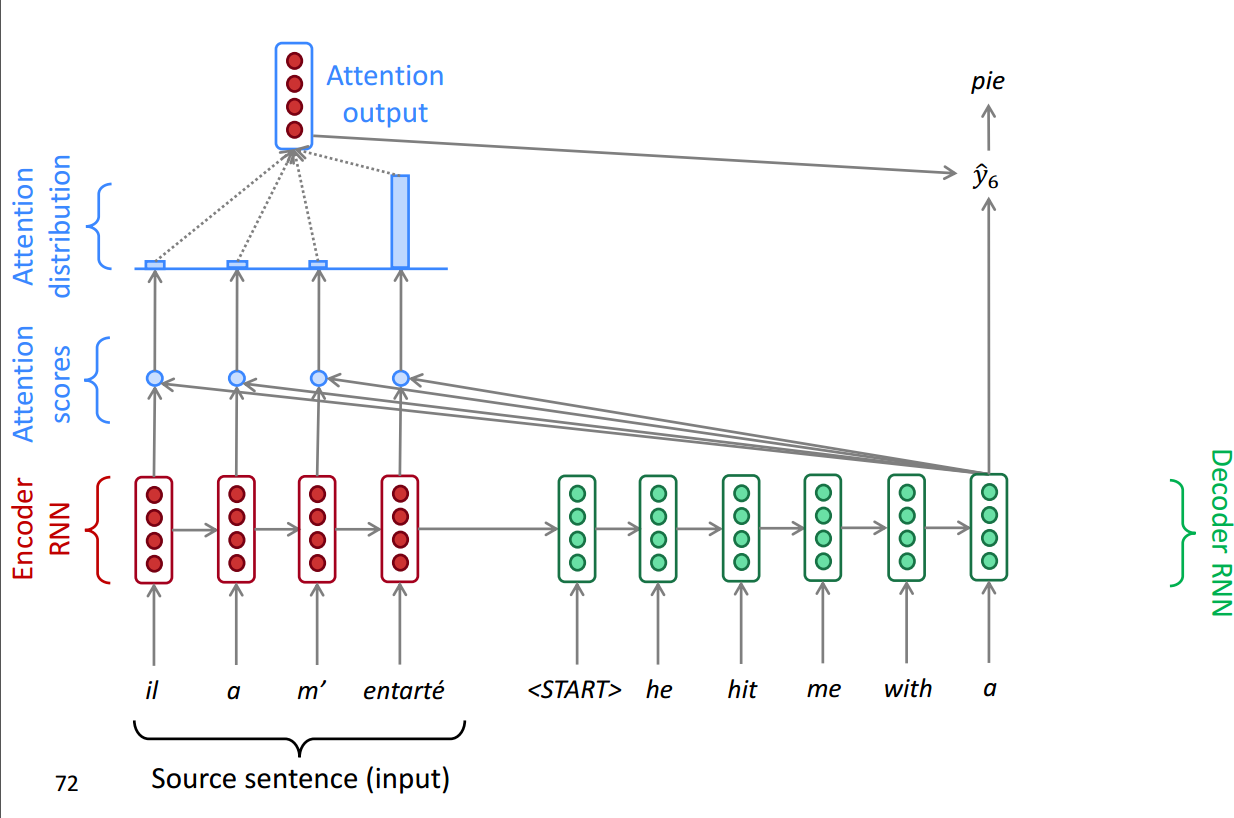
最终的结果就是这样的:
公式
公式基本上都在下面这张图上:
上面公式的过程和步骤图解基本上可以对应起来。
Attention 的优点
- 极大提升了NMT的性能
- 解决了seq2seq的瓶颈问题
- 对梯度消失问题有一定的帮助
- 提供了一些可解释性:
- 我们知道了
Decoder的每一步都在关注什么 - 相当于做了隐性的对齐
一些变体
根据上面,我们知道Attention整体基本上可以分为三步:
- 求Attention Scores
- 求Attention distribution
- 输出
而实际在第一步的时候有多种求法。
在上面的例子中,我们通过:$s_{t}^{T} \boldsymbol{h}_{i}$进行求解。而主要的求解的方法一般有三种:

可以看出来,第一种是我们上面提到的部分。
参考
cs224n 2019 Lecture 08 Machine Translation, Seq2Seq and Attention
cs224n 2017 Lecture 10
CS224n笔记10 NMT与Attention