参考文献1:《Recurrent Convolutional Neural Networks for Text Classification》
首先,直接看模型图:
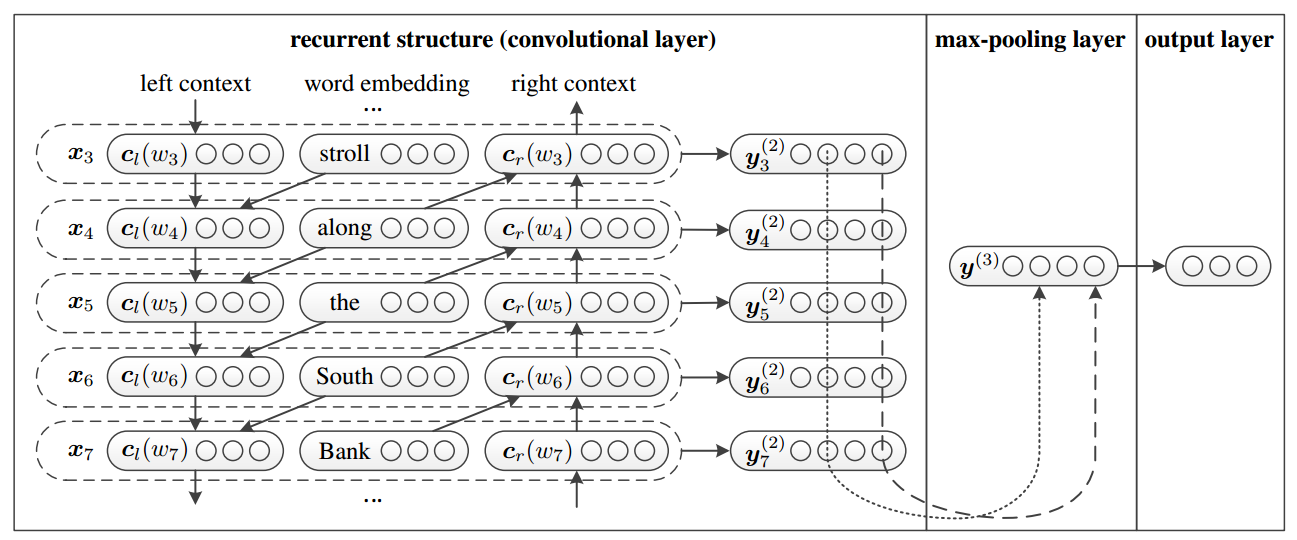
根据模型图,可以明显看出,是要用了Bi-RNN + Max-Pooling + 全连接。
根据图的公式为:
假设有一个句话D,由$w_{1}, w_{2}, \ldots, w_{n}$个单词组成,使用$p(k | D, \theta)$表示句子为类K,其中$\theta$为超参数。分别使用$\boldsymbol{c}_{l}\left(\boldsymbol{w}_{i}\right)$、$\boldsymbol{c}_{r}\left(\boldsymbol{w}_{i}\right)$分别表示单词$w_i$的左右上下文,$e\left(w_{i-1}\right)$表示词的$w_{i-1}$词向量。
最终我们有这样两个式子,来表示Bi-RNN的正反两层:
然后进行连接操作:
经过一个非线性变化:
然后对所有元素进行max-pooling:
最后接一个softmax完成分类:
这样子就将RNN和CNN结合到一起去了。
这篇论文中有一个需要注意的点,比如下面这句话:
[I like NLP]
[w1 w2 w3]
然后将这个序列输入到left RNN中,首先是w1输入进行,根据上面的公式,我们可以知道得到的结果是$c_l(w_2)$,而在最后连接层的时候,我们就不太方便将[$c_l(w_2)$;$w_2$;$c_r(w_2)$]连接起来,所以这里我们进行一个处理,将left context处理成[UNK w1 w2]。同理在right context中我们也需要处理成[w2 w3 UNK]
实现
对于上述的论文,我们使用keras进行模型复现:
1 | def loadRCNNModel(max_features, embed_size, embedding_matrix=None): |
这个模型可以对应着上面的那张图看。
同时我们还需要对数据进行适当的预处理,具体可以参考上面注意的点,我们用下面这个方法进行实现:
1 | def handle_context(doc): |
最终整体代码为
(数据可以去kaggle QIQC比赛获取)
1 | import numpy as np # linear algebra |