参考文献1:《Convolutional Neural Networks for Sentence Classification》
参考文献2:《A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification》
文章:自然语言中的CNN—TextCNN(基础篇)
CNN通常在CV领域使用较多,而在NLP领域,我们也可以使用CNN进行处理一些任务,本文将分析使用TextCNN进行文本分类。
首先先看一下参考文献一中的模型图: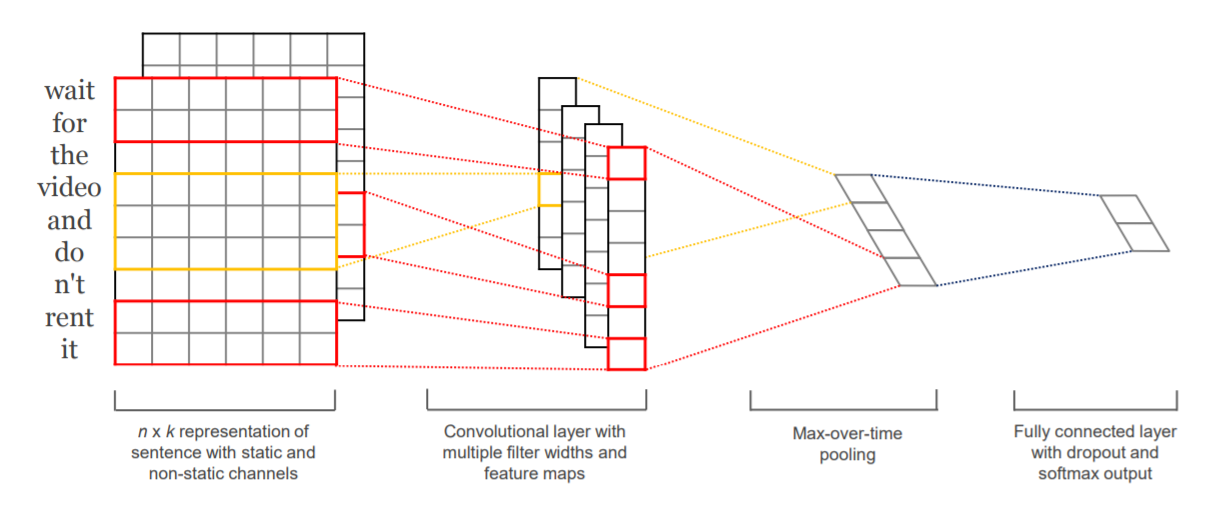
从图中可以很明显看出来整个模型分为四个方面:
- 词向量层:可以使用预训练好的词向量
- 卷积层:设置多个卷积核,其中这里的卷积核的宽度一般要和词向量的维度一致
- 池化层:将卷积层的数据进行池化,其实一般就是取最大或者取均值,构成新的维度的数据
- 全连接层:将池化层的数据输入全连接层,然后接一个softmax进行分类。这一层一般需要进行L2正则和Dropout,防止过拟合!
对于这样简单的一个网络,我们来看一下它的前向传播公式:
- 首先句子长度为$n$,$\mathbf{x}_{i} \in \mathbb{R}^{k}$, 表示句子中第 $i$个单词对应的K维的词向量。使用$\oplus$表示连接操作,那么$\mathbf{x}_{1 : n}=\mathbf{x}_{1} \oplus \mathbf{x}_{2} \oplus \ldots \oplus \mathbf{x}_{n}$可以用来表示一句话使用了词向量表示以后的样子。
- 定义一个卷积核,$\mathbf{w} \in \mathbb{R}^{h k}$ 用来在一个 $h$ 长度的窗口上进行发现新的特征。按照图上表示的卷积核进行一次卷积得到一个数字:$c_{i}$,可以用下面的式子进行表示:注意:这里进行的是内积操作
同理,多个位置进行卷积得到其中$\mathbf{c} \in \mathbb{R}^{n-h+1}$
- 然后到了池化层,非常简单,直接$\hat{c}=\max {\mathbf{c}}$
- 最后选择m个卷积核,后成一个$m$维的向量,作为全连接层的输入:$\mathbf{z}=\left[\hat{c}_{1}, \dots, \hat{c}_{m}\right]$,然后就是正常的全连接网络了:
$\hat y = softmax(\mathbf{w} \cdot \mathbf{z}+b)$
文献一种还进行了几个对比试验分别是:
- CNN-rand:作为一个基础模型,Embedding layer所有words被随机初始化,然后模型整体进行训练。
- CNN-static:模型使用预训练的word2vec初始化Embedding layer,对于那些在预训练的word2vec没有的单词,随机初始化。然后固定Embedding layer,fine-tune整个网络。
- CNN-non-static:同CNN-static,只是训练的时候,Embedding layer跟随整个网络一起训练。
- CNN-multichannel:Embedding layer有两个channel,一个channel为static,一个为non-static。然后整个网络fine-tune时只有一个channel更新参数。两个channel都是使用预训练的word2vec初始化的。
最终实验得出的结果是:
可以看出除了随机初始化Embedding layer的外,使用预训练的word2vec初始化的效果都更加好。非静态的比静态的效果好一些。总的来看,使用预训练的word2vec初始化的TextCNN,效果更好。
小结
(1)使用预训练的word2vec 、 GloVe初始化效果会更好。一般不直接使用One-hot。
(2)卷积核的大小影响较大,一般取1~10,对于句子较长的文本,则应选择大一些。
(3)卷积核的数量也有较大的影响,一般取100~600 ,同时一般使用Dropout(0~0.5)。
(4)激活函数一般选用ReLU 和 tanh。
(5)池化使用1-max pooling。
(6)随着feature map数量增加,性能减少时,试着尝试大于0.5的Dropout。
(7)评估模型性能时,记得使用交叉验证。